Un problème de riche
Transposer des données, c’est-à-dire transformer des lignes en colonnes ou des colonnes en lignes, n’est généralement pas une opération facile. Sous R, la principale difficulté vient de la multiplication de packages pour réaliser cette opération : ici nous décrirons la logique et les avantages de trois d’entre eux, {reshape2} qui est le plus ancien, {tidyr} qui est intégré au tidyverse et {cdata} qui propose une approche assez différente via un “plan de transposition”.
Commençons par créer de petits exemples de données à transposer, pour pouvoir comparer les solutions proposées par ces trois packages.
- Les données “mensuelles” contiennent une ligne par produit et une colonne par ventes mensuelles. Le beosin est de transformer en données trimestrielles, soit avec une ligne par combinaison d’un produit et d’un trimestre, soit avec une ligne par produit et une colonne par ventes trimestrielles.
mensuelles <- data.frame(produit=LETTERS[1:4],
ventes_2019_01=c(100,120,80,95),
ventes_2019_02=c(95,135,82,95),
ventes_2019_03=c(101,140,85,90),
ventes_2019_04=c(100,100,70,85),
ventes_2019_05=c(122,81,82,100),
ventes_2019_06=c(150,50,90,100)
)| produit | ventes_2019_01 | ventes_2019_02 | ventes_2019_03 | ventes_2019_04 | ventes_2019_05 | ventes_2019_06 |
|---|---|---|---|---|---|---|
| A | 100 | 95 | 101 | 100 | 122 | 150 |
| B | 120 | 135 | 140 | 100 | 81 | 50 |
| C | 80 | 82 | 85 | 70 | 82 | 90 |
| D | 95 | 95 | 90 | 85 | 100 | 100 |
- Les données “assurances” contiennent une ligne par client et deux colonnes pour chacun de ses contrats (3 maximum par client) : le type d’assurance et l’année du début de ce contrat d’assurance. On peut vouloir transformer ces données sous une forme où chaque combinaison client x contrat correspond à une ligne, avec type et année de début comme colonnes ; ou bien avec une colonne par type de contrat (AUTO, HABITATION) remplie par le nombre de contrats de chaque type.
assurances <- data.frame(client=1:4,
type_contrat1=c("AUTO","HABITATION","AUTO","AUTO"),
annee_debut_contrat1=c(2015,2017,2019,2002),
type_contrat2=c("AUTO","AUTO",NA,NA),
annee_debut_contrat2=c(2016,2019,NA,NA),
type_contrat3=c("HABITATION",NA,NA,NA),
annee_debut_contrat3=c(2018,NA,NA,NA)
)| client | type_contrat1 | annee_debut_contrat1 | type_contrat2 | annee_debut_contrat2 | type_contrat3 | annee_debut_contrat3 |
|---|---|---|---|---|---|---|
| 1 | AUTO | 2015 | AUTO | 2016 | HABITATION | 2018 |
| 2 | HABITATION | 2017 | AUTO | 2019 | NA | NA |
| 3 | AUTO | 2019 | NA | NA | NA | NA |
| 4 | AUTO | 2002 | NA | NA | NA | NA |
Avec {reshape2}
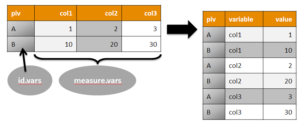
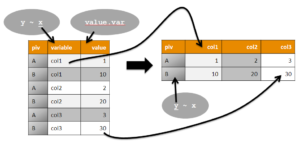
Le package {reshape2} propose deux fonctions principales : melt et dcast. La première, melt, prend une série de colonnes pour mettre leur contenu sous forme de plusieurs lignes ; des colonnes “pivot” restant orientées à l’identique – leur contenu est juste recopié – doivent être proposées. L’idée est de passer d’une table “large” (avec de nombreuses colonnes) à une table “haute” (avec de nombreuses lignes mais peu de colonnes). La seconde, dcast, réalise l’opération inverse : d’une table haute on passe à une table large.
Fontion melt
Fonction dcast
Dans melt, les deux principaux arguments, outre le data.frame à transposer, sont id.vars pour la ou les variables “pivotales” sous forme de vecteurs de type caractère contenant leur(s) nom(s), et measure.vars pour la ou les variables à transposer – là encore sous forme d’un vecteur de noms.
library(reshape2)
# étape 1 : on met la table à la verticale avec melt
# on récupère les noms des colonnes "ventesXXX" à transposer
var_ventes <- colnames(
mensuelles[grepl("^ventes",
colnames(mensuelles))])
mensuelles_vertical <- melt(mensuelles,
id.vars = "produit",
measure.vars = var_ventes)| produit | variable | value |
|---|---|---|
| A | ventes_2019_01 | 100 |
| B | ventes_2019_01 | 120 |
| C | ventes_2019_01 | 80 |
| D | ventes_2019_01 | 95 |
| A | ventes_2019_02 | 95 |
| B | ventes_2019_02 | 135 |
etc.
Dans une étape intermédiaire, nous calculons le trimestre à partir du nom de l’ancienne colonne contenu dans “variable”.
library(stringr) # fonction str_extract
mensuelles_vertical$annee <- str_extract(mensuelles_vertical$variable, "\\d{4}")
mensuelles_vertical$mois <- str_extract(mensuelles_vertical$variable, "\\d{2}$")
mensuelles_vertical$trim <- cut(as.numeric(mensuelles_vertical$mois),
breaks=c(0,3,6,9,12))
levels(mensuelles_vertical$trim) <- paste0("T",1:4)| produit | variable | value | annee | mois | trim |
|---|---|---|---|---|---|
| A | ventes_2019_01 | 100 | 2019 | 01 | T1 |
| B | ventes_2019_01 | 120 | 2019 | 01 | T1 |
| C | ventes_2019_01 | 80 | 2019 | 01 | T1 |
| D | ventes_2019_01 | 95 | 2019 | 01 | T1 |
| A | ventes_2019_02 | 95 | 2019 | 02 | T1 |
| B | ventes_2019_02 | 135 | 2019 | 02 | T1 |
etc.
Maintenant, l’étape dcast va nous permettre directement de combiner l’année et le trimestre pour nommer les nouvelles colonnes, et de sommer les ventes mensuelles d’un même trimestre d’une même année. La syntaxe de dcast s’appuie sur une formule, sous la forme “pivot ~ noms_nouvelles_colonnes” ainsi que sur des arguments indiquant quelle variable sera utilisée pour alimenter les nouvelles colonnes et quelle statistique sera appliquée à cette variable (utile si, comme ici, plusieurs valeurs sont en concurrence pour être copiée dans la même cellule : dans notre cas, toutes les ventes mensuelles d’un même produit sur un trimestre donné).
# étape 2 : on transpose avec dcast
trimestrielles <- dcast(mensuelles_vertical,
produit ~ annee + trim,
value.var = "value",
fun.aggregate = sum)| produit | 2019_T1 | 2019_T2 |
|---|---|---|
| A | 296 | 372 |
| B | 395 | 231 |
| C | 247 | 242 |
| D | 280 | 285 |
Pour un deuxième exemple, on cherche à compter les contrats de chaque type par client des données “assurances”. On commence par pivoter les colonnes dont le nom commence par “type_contrat” avec melt. Ici le package {dplyr} fournit une alternative à la sélection de colonne faite en code R {base} dans le premier exemple. Puis on élimine les lignes contenant des NA, avant de pivoter à nouveau via dcast. Ici la fonction d’agrégation est un comptage (length) et la variable à compter est déterminée automatiquement par dcast – ce qui n’a pas vraiment d’impact sur le résultat puisqu’on compte les lignes.
library(dplyr) # pour les fonctions select et starts_with
assurances_types <- melt(assurances, id.vars = "client",
measure.vars = colnames(select(assurances,
starts_with("type_contrat"))))
assurances_types <- assurances_types[!is.na(assurances_types$value),]
nb_assurances <- dcast(assurances_types,
client ~ value,
fun.aggregate = length)| client | AUTO | HABITATION |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 1 | 1 |
| 3 | 1 | 0 |
| 4 | 1 | 0 |
Avec {tidyr}
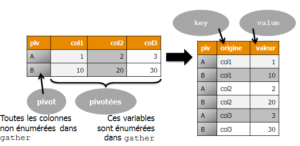
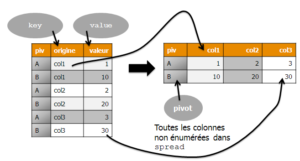
Sur le principe, {tidyr} et {reshape2} sont assez proches ; on y retrouve un couple de fonctions dont les rôles sont semblables : melt = gather, dcast = spread. Les principales différences entre {reshape2} et {tidyr} sont : * que {tidyr} ne demande pas d’expliciter le rôle de toutes les variables mais les déduit, ce qui oblige à éliminer en amont les variables inutiles à la transposition * que la fonction équivalente à dcast, spread, n’aggrège pas plusieurs valeurs avec une fonction statistique. Cette opération doit être réalisée en amont pour n’avoir qu’une valeur à copier par cellule créée * la syntaxe très tidyverse de {tidyr} qui fait usage de NSE (Non Standard Evaluation), avec des noms de variables qui sont fournis tels quels, sans guillemets ni précision du data.frame qui les contient. L’utilisation courante est allégée mais l’automatisation et le paramétrage (avec !! et éventuellement enquo si on veut s’en servir dans une fonction) s’en trouvent compliqués.
Fonction gather
Fonction spread
Dans le premier exemple, on reprend exactement le même fonctionnement que melt, mais le code est présenté différemment. D’une part on enchaîne les opérations avec l’opérateur %>% de {magrittr} pour reprendre la syntaxe classique du tidyverse. D’autre part, les arguments de gather sont ici “en creux” : on indique quelle variable ne pivote pas (on remarque le signe moins devant son nom), ce sera donc celle qui servira de pivot. Autres arguments nécessaires à gather : les noms des colonnes créées, ici celle qui contient les anciens noms de colonnes et les anciennes valeurs de ces colonnes. Nous reprenons les noms utilisés par melt pour que l’étape intermédiaire (récupération des années et des mois, calcul du trimestre) soit écrite exactement à l’identique.
library(tidyr)
mensuelles_vertical <- mensuelles %>%
gather(-produit,
key="variable", value="value")
# on récupère les années, les mois et les trimestres à partir des anciens noms de variables
mensuelles_vertical$annee <- str_extract(mensuelles_vertical$variable, "\\d{4}")
mensuelles_vertical$mois <- str_extract(mensuelles_vertical$variable, "\\d{2}$")
mensuelles_vertical$trim <- cut(as.numeric(mensuelles_vertical$mois),
breaks=c(0,3,6,9,12))
levels(mensuelles_vertical$trim) <- paste0("T",1:4)| produit | variable | value | annee | mois | trim |
|---|---|---|---|---|---|
| A | ventes_2019_01 | 100 | 2019 | 01 | T1 |
| B | ventes_2019_01 | 120 | 2019 | 01 | T1 |
| C | ventes_2019_01 | 80 | 2019 | 01 | T1 |
| D | ventes_2019_01 | 95 | 2019 | 01 | T1 |
| A | ventes_2019_02 | 95 | 2019 | 02 | T1 |
| B | ventes_2019_02 | 135 | 2019 | 02 | T1 |
etc.
La fonction spread, équivalente à dcast, ne sachant pas agréger les données, une étape de {dplyr} avec group_by et summarise prend en charge cet aspect. On en profite pour créer les noms des futures colonnes. Dans spread on indique ensuite la variable contenant les futurs noms de colonnes (argument key) et les futurs contenus (argument value). Les autres variables du data.frame sont considérées comme des pivots. Dans notre cas, ce sera “produit”, les autres variables (annee, mois et trim) ayant été éliminées implicitement lors du group_by.
library(dplyr)
mensuelles_trim_vertical <- mensuelles_vertical %>%
group_by(produit,
nom_var = paste("total",
annee,
trim,
sep="_")) %>%
summarise(total = sum(value))
mensuelles_trim <- mensuelles_trim_vertical %>%
spread(key="nom_var",
value="total")| produit | total_2019_T1 | total_2019_T2 |
|---|---|---|
| A | 296 | 372 |
| B | 395 | 231 |
| C | 247 | 242 |
| D | 280 | 285 |
Le second exemple, avec les données d’assurances, reprend la même trame qu’avec {reshape2} : sélection et transposition des colonnes dont le nom commence par “type”, puis agrégation (ici en {dplyr}) et enfin transposition en sens inverse.
assurances_type <- assurances %>%
select(client,
starts_with("type")) %>%
gather(-client,
key="ancien_nom",
value="type_contrat")## Warning: attributes are not identical across measure variables;
## they will be dropped| client | ancien_nom | type_contrat |
|---|---|---|
| 1 | type_contrat1 | AUTO |
| 2 | type_contrat1 | HABITATION |
| 3 | type_contrat1 | AUTO |
| 4 | type_contrat1 | AUTO |
| 1 | type_contrat2 | AUTO |
| 2 | type_contrat2 | AUTO |
etc.
nb_assurances <- assurances_type %>%
filter(!is.na(type_contrat)) %>%
group_by(client, type_contrat) %>%
count() %>%
spread(key="type_contrat",
value="n")| client | AUTO | HABITATION |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 1 | 1 |
| 3 | 1 | NA |
| 4 | 1 | NA |
Nouveautés de {tidyr} version 1.x
Les fonctions pivot_longer et pivot_wider sont appelées à remplacer à terme gather et spread (respectivement), en ayant des noms a priori un peu plus intuitifs et de nouvelles fonctionnalités.
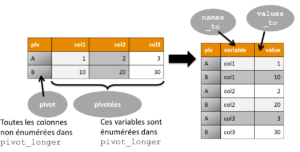
Fonction pivot_longer
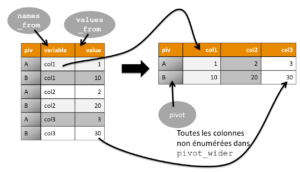
Fonction pivot_wider
Commençons par pivot_longer qui reprend la logique de gather (on indique quelle variable ne pivote pas, ce sera donc celle qui servira de pivot) et les options key et value sont ici nommées names_to et values_to.
library(tidyr)
mensuelles_vertical <- mensuelles %>%
pivot_longer(-produit,
names_to="mois", values_to="ventes")| produit | mois | ventes |
|---|---|---|
| A | ventes_2019_01 | 100 |
| A | ventes_2019_02 | 95 |
| A | ventes_2019_03 | 101 |
| A | ventes_2019_04 | 100 |
| A | ventes_2019_05 | 122 |
| A | ventes_2019_06 | 150 |
Mais on peut expliciter les colonnes à pivoter avec l’option cols et utiliser les fonctions de sélection rapide que propose dplyr::select (starts_with, ends_with, contains et matches). La variable pivot reste obtenue par déduction.
library(tidyr)
mensuelles_vertical <- mensuelles %>%
pivot_longer(cols=starts_with("ventes"),
names_to="mois", values_to="ventes")| produit | mois | ventes |
|---|---|---|
| A | ventes_2019_01 | 100 |
| A | ventes_2019_02 | 95 |
| A | ventes_2019_03 | 101 |
| A | ventes_2019_04 | 100 |
| A | ventes_2019_05 | 122 |
| A | ventes_2019_06 | 150 |
Dans cette configuration, on peut se débarrasser d’une partie des noms de variables pivotées avec l’option names_prefix.
library(tidyr)
mensuelles_vertical <- mensuelles %>%
pivot_longer(cols=starts_with("ventes"),
names_to="mois", values_to="ventes",
names_prefix="ventes_")| produit | mois | ventes |
|---|---|---|
| A | 2019_01 | 100 |
| A | 2019_02 | 95 |
| A | 2019_03 | 101 |
| A | 2019_04 | 100 |
| A | 2019_05 | 122 |
| A | 2019_06 | 150 |
L’option names_pattern permet quelque chose d’un peu différent, en conjonction avec un vecteur de noms dans names_to : il s’agit de décrire les noms des colonnes pivotées par une expression régulière où des blocs seront délimités par une paire de parenthèse. Le premier bloc alimentera la première colonne citée dans names_to, le deuxième bloc alimentera la 2e colonne, etc. Cela évitera de devoir extraire les informations a posteriori.
library(tidyr)
mensuelles_vertical <- mensuelles %>%
pivot_longer(cols=starts_with("ventes"),
names_to=c("annee","mois"),
names_pattern="ventes_(\\d{4})_(\\d{2})",
values_to="ventes")| produit | annee | mois | ventes |
|---|---|---|---|
| A | 2019 | 01 | 100 |
| A | 2019 | 02 | 95 |
| A | 2019 | 03 | 101 |
| A | 2019 | 04 | 100 |
| A | 2019 | 05 | 122 |
| A | 2019 | 06 | 150 |
On peut également manipuler sur ce principe les données d’assurance. On utilisera ici un mot-clé spécial, “.value”, dans names_to pour créer autant de colonnes que le premier bloc de names_pattern renverra de textes distincts.
library(tidyr)
assurances_types <- assurances %>%
pivot_longer(- client,
names_to=c(".value","num_contrat"),
names_pattern="(.+)_contrat(\\d+)")| client | num_contrat | type | annee_debut |
|---|---|---|---|
| 1 | 1 | AUTO | 2015 |
| 1 | 2 | AUTO | 2016 |
| 1 | 3 | HABITATION | 2018 |
| 2 | 1 | HABITATION | 2017 |
| 2 | 2 | AUTO | 2019 |
| 2 | 3 | NA | NA |
| 3 | 1 | AUTO | 2019 |
| 3 | 2 | NA | NA |
| 3 | 3 | NA | NA |
| 4 | 1 | AUTO | 2002 |
| 4 | 2 | NA | NA |
| 4 | 3 | NA | NA |
Dans l’autre sens, c’est donc la fonction pivot_wider qui remplace spread. Ses options ont des noms cohérents avec ceux de pivot_longer puisqu’elles se nomment names_from et values_from.
mensuelles_2 <- mensuelles_vertical %>%
pivot_wider(names_from="produit",
values_from="ventes")| annee | mois | A | B | C | D |
|---|---|---|---|---|---|
| 2019 | 01 | 100 | 120 | 80 | 95 |
| 2019 | 02 | 95 | 135 | 82 | 95 |
| 2019 | 03 | 101 | 140 | 85 | 90 |
| 2019 | 04 | 100 | 100 | 70 | 85 |
| 2019 | 05 | 122 | 81 | 82 | 100 |
| 2019 | 06 | 150 | 50 | 90 | 100 |
Comme dans dcast, il est possible d’agréger avec l’option values_fn.
trim1 <- mensuelles_vertical %>% dplyr::select(-mois) %>%
pivot_wider(names_from="produit",
values_from="ventes",
values_fn=list(ventes=sum))| annee | A | B | C | D |
|---|---|---|---|---|
| 2019 | 668 | 626 | 489 | 565 |
Avec {cdata}
Le package {cdata} n’est pas relié au tidyverse et son fonctionnement est assez différent. On retrouve dans ce package des fonctions équivalentes à melt/gather (ici appelée rowrecs_to_blocks) et dcast/spread (ici, blocks_to_rowrecs, assez logiquement) ; mais la valeur ajoutée de ce package est la possibilité de définir le résultat attendu via un data.frame de contrôle qui engendrera à son tour une fonction pour transformer les données initiales dans la forme voulue.
Pour illustrer cette fonctionnalité spécifique, nous allons travailler sur les données “assurances” et les transformer d’une manière nouvelle : une observation par client et numéro du contrat pour ce client, et pour chaque ligne, le type de contrat et son année de début. Avec {tidyr} et {reshape2}, il faudrait plusieurs étapes de transposition, par bloc d’informations (les types de contrat séparément des années de début) puis une jointure pour associer les deux à nouveau. Avec {cdata} la transformation, qu’on prépare pas à pas avec une description de l’attendu et une fonction de transformation ad hoc, s’effectue en un seul passage sur les données (pratique si elles sont volumineuses).
library(cdata)
library(wrapr) # fonction qchar_frame et opérateur %.>%
resultat_attendu <- qchar_frame(
"num_ct" , "type" , "annee_debut" |
"1" , type_contrat1 , annee_debut_contrat1 |
"2" , type_contrat2 , annee_debut_contrat2 |
"3" , type_contrat3 , annee_debut_contrat3)On a contruit l’aspect d’un bloc de lignes correspondant à un client en indiquant comment les colonnes d’origine peuplent ce bloc.
| num_ct | type | annee_debut |
|---|---|---|
| 1 | type_contrat1 | annee_debut_contrat1 |
| 2 | type_contrat2 | annee_debut_contrat2 |
| 3 | type_contrat3 | annee_debut_contrat3 |
On indique maintenant que ce sont des blocs de clients et on construit la fonction de transposition ad hoc. On l’applique ensuite avec un enchaînement de traitements assez semblable à celui de {magrittr} mais avec un opérateur légèrement différent, %.>%, qui provient du package {wrapr}. Comme avec %>% le nom du data.frame transmis le long de l’enchaînement est symbolisé par un point.
transposition <- rowrecs_to_blocks_spec(resultat_attendu,
recordKeys = "client")
# on applique la transformation et on élimine les lignes où il n'y a pas de 2e ou 3e contrat
assurance_contrat <- assurances %.>% transposition %.>% .[!is.na(.$type),]| client | num_ct | type | annee_debut |
|---|---|---|---|
| 1 | 1 | AUTO | 2015 |
| 1 | 2 | AUTO | 2016 |
| 1 | 3 | HABITATION | 2018 |
| 2 | 1 | HABITATION | 2017 |
| 2 | 2 | AUTO | 2019 |
| 3 | 1 | AUTO | 2019 |
| 4 | 1 | AUTO | 2002 |