De nombreux cas de figure dans R nécessitent de réorganiser les données de manière à changer ce que représente une ligne dans un data.frame : tableaux croisés statistiques, construction de graphiques, opération à réaliser systématiquement sur N colonnes. Des pivots (en général partiels) dans les données sont alors à envisager ; nous verrons ici les fonctions pivot_longer et pivot_wider du package {tidyr}, élément du méta-package {tidyverse}.
A noter que ce document est une version plus récente et plus courte d’un article plus général dédié aux transpositions avec R que vous pouvez toujours consulter ici.
Plus de lignes et moins de colonnes
Une première fonction, pivot_longer, permet de transformer une série de colonnes en une démultiplication de lignes. On change ce que représente une ligne pour se faciliter des manipulations ultérieures.
Par exemple, dans une base de lycéens avec une colonne par enseignement optionnel, on va transformer en une base où chaque ligne représente une option d’un lycéen, les options choisies s’étant empilées dans une seule colonne. Cela facilitera les comptages des options choisies (peu importe si « Arts du cirque » ou « Maths » sont choisies en 1e, 2e ou 3e option). De la même manière, cette manipulation permet de réorganiser une base familiale : au départ une ligne par famille et une colonne par date de naissance de chaque enfant ; à l’arrivée une ligne par enfant, avec les dates de naissance dans une seule colonne.
pivot_longer( < données, >
cols = colonnes_pivotees,
< names_to = "nom1", >
< values_to = "nom2" > )
La fonction pivot_longer a pour premier argument un data.frame. On peut le citer explicitement ou le sous-entendre par un enchaînement avec le connecteur %>% classique du {tidyverse}.
Le seul autre argument obligatoire est la liste des colonnes à pivoter, dans cols. Elles sont citées sans guillemets, sous forme de vecteur. Les fonctions sélectrices de dplyr::select (starts_with, ends_with, contains, matches) sont également utilisables ici.

On peut indiquer avec les options names_to et values_to dans quelle colonne seront stockés les anciens noms de colonnes et dans quelle colonne s’empileront les valeurs pivotées.
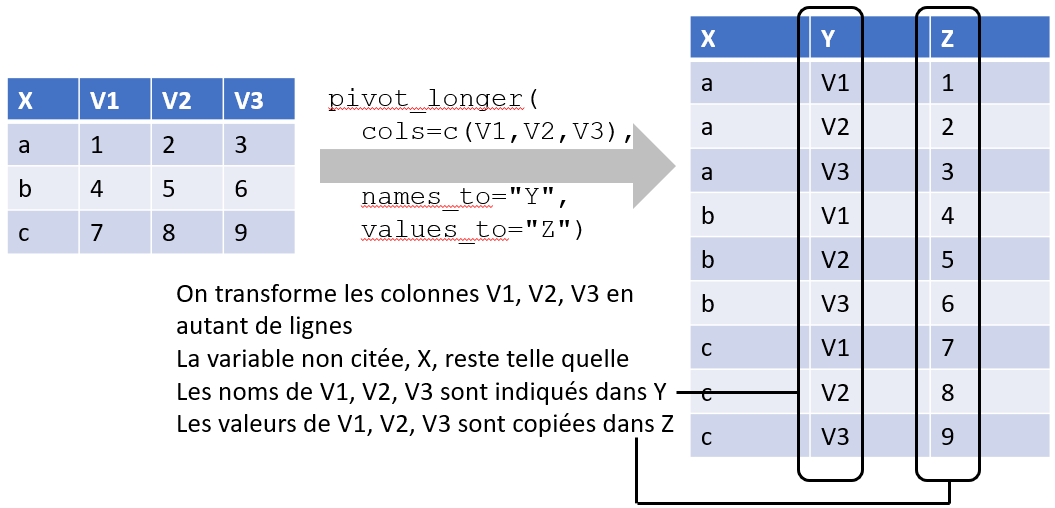
La subtilité dans pivot_longer est qu’on n’indique pas explicitement quelles colonnes restent telles quelles. Ce sont toutes celles qui ne sont pas indiquées dans cols. Il est donc souvent nécessaire de faire une sélection de colonnes en amont de pivot_longer.

On peut opter dans cols pour une sélection négative : dans ce cas ce sont les colonnes qui ne bougent pas, toutes les autres étant pivotées.
Plus de colonnes, moins de lignes
On peut penser à la fonction pivot_wider comme le symétrique de la précédente. C’est globalement le cas, mais il est souvent plus simple de l’appréhender comme la construction d’un tableau croisé, sur le modèle des TCD que propose Excel.
pivot_wider( < données, >
id_cols = en_lignes,
names_from = en_colonnes,
values_from = dans_les_cellules,
< values_fn = fonction_agrégation, >
< values_fill = valeur_par_défaut > )
Comme pour pivot_longer, on commence par indiquer la source de données, explicitement ou via %>%. On indique ensuite, comme pour un tableau croisé, comment se construisent les lignes, les colonnes et le contenu des cellules du tableau.

Les options values_fn et values_fill permettent respectivement de combiner des valeurs s’il y en a plusieurs qui pointent vers la même cellule (une somme, une moyenne, une concaténation avec paste, un comptage avec length, etc.) et la valeur à indiquer dans une cellule vers laquelle ne pointerait aucune valeur.

Un cas particulier se rencontre si on a plusieurs colonnes fournissant des valeurs, par exemple deux statistiques différentes. Le résultat démultipliera les colonnes du tableau par le nombre de statistiques à transposer.

Des options supplémentaires (names_sep, names_glue, names_sort) permettent alors de former librement les noms de ces colonnes combinées pour un résultat qui s’avèrera facile à utiliser.
